Archive
web scraping: BS4 supports CSS select
BeautifulSoup is an excellent tool for web scraping. The development of BeautifulSoup 3 stopped in 2012, its author concentrates on BeautifulSoup 4 since then.
In this post I want to show how to use CSS selectors. With CSS selectors you can select part of a webpage, which is what we need when we do web scraping. Another possibility is to use XPath. I find CSS selectors easier to use. You can read this post too for a comparison: Why CSS Locators are the way to go vs XPath.
Exercise
Let’s go through a concrete example, that way it will be easier to understand.
The page http://developerexcuses.com/ prints a funny line that developers can use as an excuse. Let’s extract this line.
Visit the page, start Firebug, and click on the line (steps 1 and 2 on the figure below):
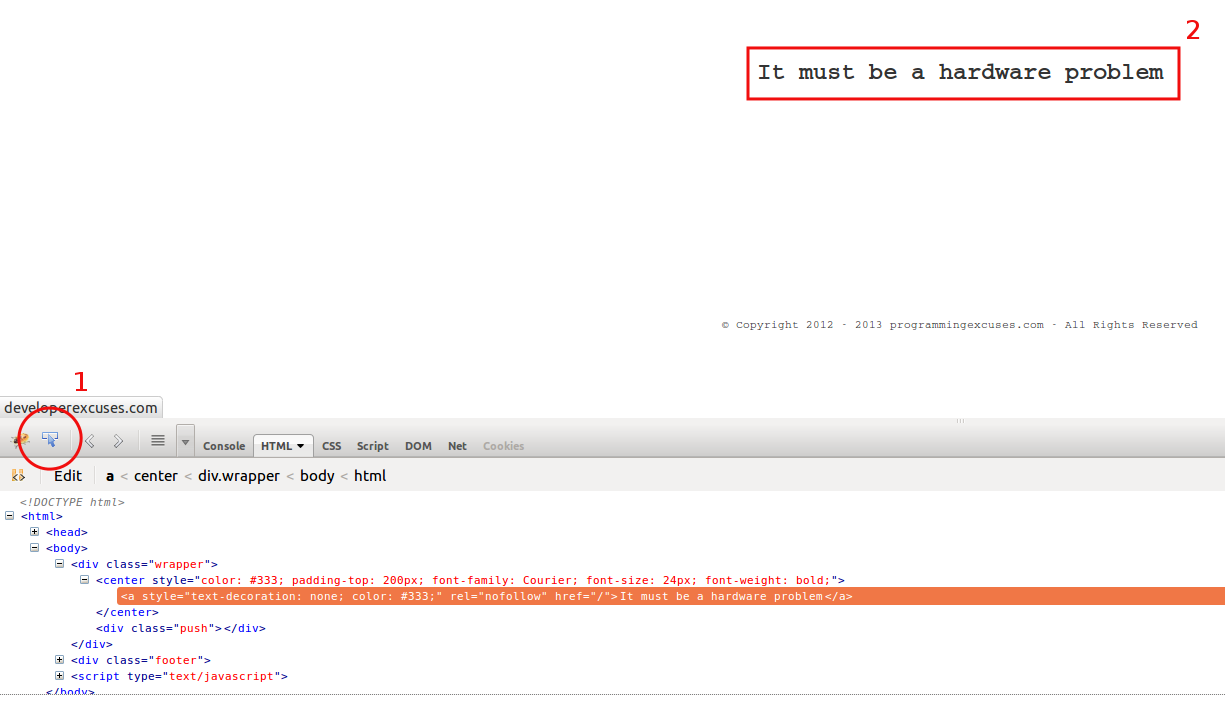
Right click on the orange line (“<a style=...“) and choose “Copy CSS Path”. Now the CSS path of the selected HTML element is on the clipboard, which is “html body div.wrapper center a” in this example.
Now let’s write a script that prints this part of the HTML source:
import requests
import bs4
def main():
r = requests.get("http://developerexcuses.com/")
soup = bs4.BeautifulSoup(r.text)
print soup.select("html body div.wrapper center a")[0].text
if __name__ == "__main__":
main()


You must be logged in to post a comment.