Archive
get the title of a web page
Problem
You need the title of a web page.
Solution
from bs4 import BeautifulSoup soup = BeautifulSoup(html) print soup.title.string
I found the solution here.
web scraping: BS4 supports CSS select
BeautifulSoup is an excellent tool for web scraping. The development of BeautifulSoup 3 stopped in 2012, its author concentrates on BeautifulSoup 4 since then.
In this post I want to show how to use CSS selectors. With CSS selectors you can select part of a webpage, which is what we need when we do web scraping. Another possibility is to use XPath. I find CSS selectors easier to use. You can read this post too for a comparison: Why CSS Locators are the way to go vs XPath.
Exercise
Let’s go through a concrete example, that way it will be easier to understand.
The page http://developerexcuses.com/ prints a funny line that developers can use as an excuse. Let’s extract this line.
Visit the page, start Firebug, and click on the line (steps 1 and 2 on the figure below):
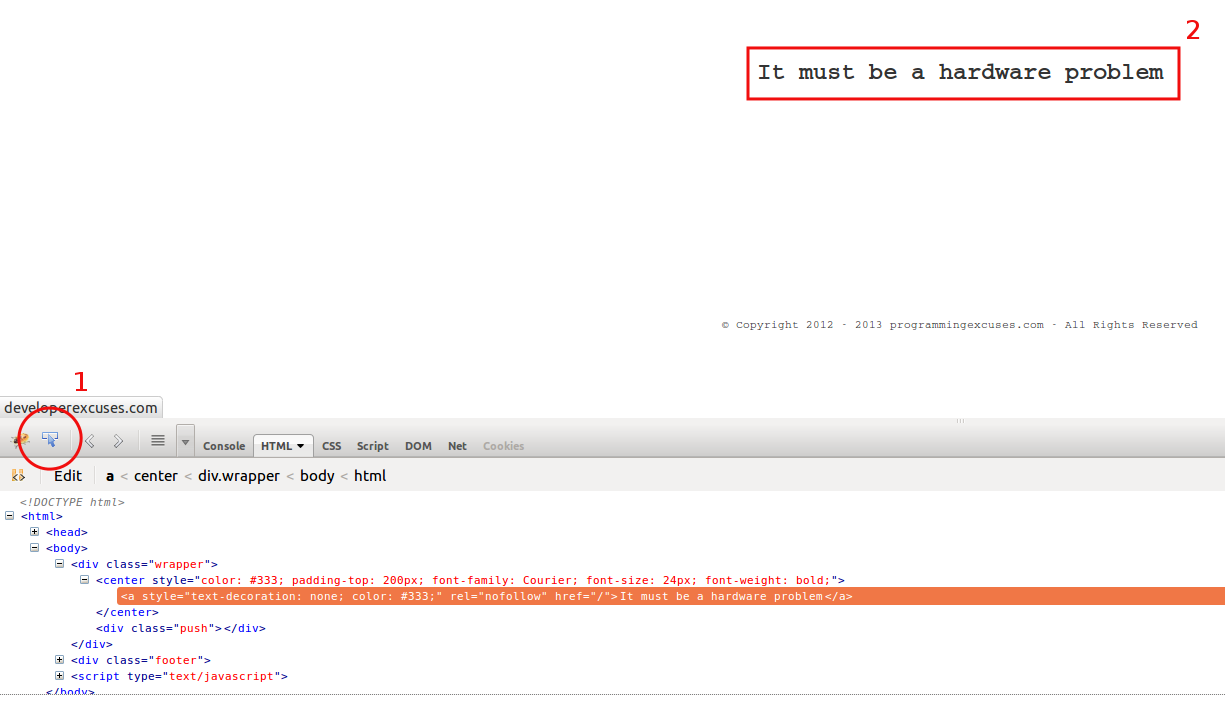
Right click on the orange line (“<a style=...“) and choose “Copy CSS Path”. Now the CSS path of the selected HTML element is on the clipboard, which is “html body div.wrapper center a” in this example.
Now let’s write a script that prints this part of the HTML source:
import requests
import bs4
def main():
r = requests.get("http://developerexcuses.com/")
soup = bs4.BeautifulSoup(r.text)
print soup.select("html body div.wrapper center a")[0].text
if __name__ == "__main__":
main()
BeautifulSoup: _detectEncoding error
Problem
While parsing an HTML page with BeautifulSoup, I got a similar error message:
File ".../BeautifulSoup.py", line 1915, in _detectEncoding
'^<\?.*encoding=[\'"](.*?)[\'"].*\?>').match(xml_data)
TypeError: expected string or buffer
In the code I had this:
text = get_page(url) soup = BeautifulSoup(text)
Solution
text = get_page(url) text = str(text) # here is the trick soup = BeautifulSoup(text)
Tip from here.
BeautifulSoup with CssSelect? Yes!
(20131215) This post is out-of-date. BeautifulSoup 4 has built-in support for CSS selectors. Check out this post.
A few days ago I started to explore lxml (it’s been on my list for a long time) and I really like its CSS selector. As I used BeautifulSoup a lot in the past, I wondered if it were possible to add this functionality to BS. I made a quick search on Google and here is what I found: https://code.google.com/p/soupselect/.
“A single function, select(soup, selector), that can be used to select items from a BeautifulSoup instance using CSS selector syntax. Currently supports type selectors, class selectors, id selectors, attribute selectors and the descendant combinator.”
Just what I needed :) You can also patch BS and integrate this new functionality:
>>> from BeautifulSoup import BeautifulSoup as Soup
>>> import soupselect; soupselect.monkeypatch()
>>> import urllib
>>> soup = Soup(urllib.urlopen('http://slashdot.org/'))
>>> soup.findSelect('div.title h3')
[</pre>
<h3>...
Prettify HTML with BeautifulSoup
With the Python library BeautifulSoup (BS), you can extract information from HTML pages very easily. However, there is one thing you should keep in mind: HTML pages are usually malformed. BS tries to correct an HTML page, but it means that BS’s internal representation of the HTML page can be slightly different from the original source. Thus, when you want to localize a part of an HTML page, you should work with the internal representation.
The following script takes an HTML and prints it in a corrected form, i.e. it shows how BS stores the given page. You can also use it to prettify the source:
#!/usr/bin/env python
# prettify.py
# Usage: prettify <URL>
import sys
import urllib
from BeautifulSoup import BeautifulSoup
class MyOpener(urllib.FancyURLopener):
version = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15'
def process(url):
myopener = MyOpener()
#page = urllib.urlopen(url)
page = myopener.open(url)
text = page.read()
page.close()
soup = BeautifulSoup(text)
return soup.prettify()
# process(url)
def main():
if len(sys.argv) == 1:
print "Jabba's HTML Prettifier v0.1"
print "Usage: %s <URL>" % sys.argv[0]
sys.exit(-1)
# else, if at least one parameter was passed
print process(sys.argv[1])
# main()
if __name__ == "__main__":
main()
You can find the latest version of the script at https://github.com/jabbalaci/Bash-Utils.
Get the RottenTomatoes rating of a movie
Problem
In the previous post we saw how to extract the IMDB rating of a movie. Now let’s see the same thing with the RottenTomatoes website. Their rating looks like this:

Solution
Download link: https://github.com/jabbalaci/Movie-Ratings. Source code:
#!/usr/bin/env python
# RottenTomatoesRating
# Laszlo Szathmary, 2011 (jabba.laci@gmail.com)
from BeautifulSoup import BeautifulSoup
import sys
import re
import urllib
import urlparse
class MyOpener(urllib.FancyURLopener):
version = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15'
class RottenTomatoesRating:
# title of the movie
title = None
# RT URL of the movie
url = None
# RT tomatometer rating of the movie
tomatometer = None
# RT audience rating of the movie
audience = None
# Did we find a result?
found = False
# for fetching webpages
myopener = MyOpener()
# Should we search and take the first hit?
search = True
# constant
BASE_URL = 'http://www.rottentomatoes.com'
SEARCH_URL = '%s/search/full_search.php?search=' % BASE_URL
def __init__(self, title, search=True):
self.title = title
self.search = search
self._process()
def _search_movie(self):
movie_url = ""
url = self.SEARCH_URL + self.title
page = self.myopener.open(url)
result = re.search(r'(/m/.*)', page.geturl())
if result:
# if we are redirected
movie_url = result.group(1)
else:
# if we get a search list
soup = BeautifulSoup(page.read())
ul = soup.find('ul', {'id' : 'movie_results_ul'})
if ul:
div = ul.find('div', {'class' : 'media_block_content'})
if div:
movie_url = div.find('a', href=True)['href']
return urlparse.urljoin( self.BASE_URL, movie_url )
def _process(self):
if not self.search:
movie = '_'.join(self.title.split())
url = "%s/m/%s" % (self.BASE_URL, movie)
soup = BeautifulSoup(self.myopener.open(url).read())
if soup.find('title').contents[0] == "Page Not Found":
url = self._search_movie()
else:
url = self._search_movie()
try:
self.url = url
soup = BeautifulSoup( self.myopener.open(url).read() )
self.title = soup.find('meta', {'property' : 'og:title'})['content']
if self.title: self.found = True
self.tomatometer = soup.find('span', {'id' : 'all-critics-meter'}).contents[0]
self.audience = soup.find('span', {'class' : 'meter popcorn numeric '}).contents[0]
if self.tomatometer.isdigit():
self.tomatometer += "%"
if self.audience.isdigit():
self.audience += "%"
except:
pass
if __name__ == "__main__":
if len(sys.argv) == 1:
print "Usage: %s 'Movie title'" % (sys.argv[0])
else:
rt = RottenTomatoesRating(sys.argv[1])
if rt.found:
print rt.url
print rt.title
print rt.tomatometer
print rt.audience
Usage:
The constructor has an optional parameter, which is True by default (search=True). It means that first we use the search function of the RT website and then we try to follow the first link. If search=False, the script tries to access the movie page directly. If it fails, then it falls back to the first case, i.e. it will try to find the movie via search.
Which version is better? It depends :) If there are several movies with the same title, then with search=True you will get the latest movie. If search=False, then you will usually get the oldest movie with that title.
For instance, for me “Star Wars” means episode 4, thus with the title “star wars”, search=False will return the relevant hit. But for “up in the air”, I would like to get the movie from 2009, not from 1940, thus in this case search=True would be better.
If you are in doubt, use the default case, i.e. search=True.
Related links
Update (20110329):
You will find the latest version of the script at https://github.com/jabbalaci/Movie-Ratings.
[ @reddit ]
Get the IMDB rating of a movie
Problem
You want to get the IMDB rating of a movie. For instance, you have a large collection of movies, and you want to figure out their ratings. An IMDB rating looks like this:
 Solution
Solution
Here is a script that extracts the rating of a movie from IMDB. The script was inspired by the work of Rag Sagar.
Download link: https://github.com/jabbalaci/Movie-Ratings. Source code:
#!/usr/bin/env python
# ImdbRating
import os
import sys
import re
import urllib
import urlparse
from mechanize import Browser
from BeautifulSoup import BeautifulSoup
class MyOpener(urllib.FancyURLopener):
version = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15'
class ImdbRating:
# title of the movie
title = None
# IMDB URL of the movie
url = None
# IMDB rating of the movie
rating = None
# Did we find a result?
found = False
# constant
BASE_URL = 'http://www.imdb.com'
def __init__(self, title):
self.title = title
self._process()
def _process(self):
movie = '+'.join(self.title.split())
br = Browser()
url = "%s/find?s=tt&q=%s" % (self.BASE_URL, movie)
br.open(url)
if re.search(r'/title/tt.*', br.geturl()):
self.url = "%s://%s%s" % urlparse.urlparse(br.geturl())[:3]
soup = BeautifulSoup( MyOpener().open(url).read() )
else:
link = br.find_link(url_regex = re.compile(r'/title/tt.*'))
res = br.follow_link(link)
self.url = urlparse.urljoin(self.BASE_URL, link.url)
soup = BeautifulSoup(res.read())
try:
self.title = soup.find('h1').contents[0].strip()
self.rating = soup.find('span',attrs='rating-rating').contents[0]
self.found = True
except:
pass
# class ImdbRating
if __name__ == "__main__":
if len(sys.argv) == 1:
print "Usage: %s 'Movie title'" % (sys.argv[0])
else:
imdb = ImdbRating(sys.argv[1])
if imdb.found:
print imdb.url
print imdb.title
print imdb.rating
Related links
- Get the RottenTomatoes rating of a movie
- IMDbPY provides lots of possibilities if you want to retrieve and manage IMDB data. Undoubtedly, IMDbPY is a more professional (but heavier) solution. Can be installed via PyPI.
Update (20110329):
You will find the latest version of the script at https://github.com/jabbalaci/Movie-Ratings.
[ @reddit ]
Related posts (update 20120222)
- Get IMDB ratings without any scraping (at the end of this post you’ll find a much shorter Python code too)
Extract all links from a web page
Problem
You want to extract all the links from a web page. You need the links in absolute path format since you want to further process the extracted links.
Solution
Unix commands have a very nice philosophy: “do one thing and do it well”. Keeping that in mind, here is my link extractor:
#!/usr/bin/env python
# get_links.py
import re
import sys
import urllib
import urlparse
from BeautifulSoup import BeautifulSoup
class MyOpener(urllib.FancyURLopener):
version = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15'
def process(url):
myopener = MyOpener()
#page = urllib.urlopen(url)
page = myopener.open(url)
text = page.read()
page.close()
soup = BeautifulSoup(text)
for tag in soup.findAll('a', href=True):
tag['href'] = urlparse.urljoin(url, tag['href'])
print tag['href']
# process(url)
def main():
if len(sys.argv) == 1:
print "Jabba's Link Extractor v0.1"
print "Usage: %s URL [URL]..." % sys.argv[0]
sys.exit(-1)
# else, if at least one parameter was passed
for url in sys.argv[1:]:
process(url)
# main()
if __name__ == "__main__":
main()
You can find the up-to-date version of the script here.
The script will print the links to the standard output. The output can be refined with grep for instance.
Troubleshooting
The HTML parsing is done with the BeautifulSoup (BS) library. If you get an error, i.e. BeautifulSoup cannot parse a tricky page, download the latest version of BS and put BeautifulSoup.py in the same directory where get_links.py is located. I had a problem with the version that came with Ubuntu 10.10 but I could solve the problem by upgrading to the latest version of BeautifulSoup.
Update (20110414): To update BS, first remove the package python-beautifulsoup with Synaptic, then install the latest version from PyPI: sudo pip install beautifulsoup.
Examples
Basic usage: get all links on a given page.
./get_links.py http://www.reddit.com/r/Python
Basic usage: get all links from an HTML file. Yes, it also works on local files.
./get_links.py index.html
Number of links.
./get_links.py http://www.reddit.com/r/Python | wc -l
Filter result and keep only those links that you are interested in.
./get_links.py http://www.beach-hotties.com/ | grep -i jpg
Eliminate duplicates.
./get_links.py http://www.beach-hotties.com/ | sort | uniq
Note: if the URL contains the special character “&“, then put the URL between quotes.
./get_links.py "http://www.google.ca/search?hl=en&source=hp&q=python&aq=f&aqi=g10&aql=&oq="
Open (some) extracted links in your web browser. Here I use the script “open_in_tabs.py” that I introduced in this post. You can also download “open_in_tabs.py” here.
./get_links.py http://www.beach-hotties.com/ | grep -i jpg | sort | uniq | ./open_in_tabs.py
Update (20110507)
You might be interested in another script called “get_images.py” that extracts all image links from a webpage. Available here.


You must be logged in to post a comment.